


Next: Motor input
Up: Three-layers sensory-motor model
Previous: Three-layers sensory-motor model
A CCD camera gives pictures of the environment.
High curvature points (corners ...) are extracted from the
gradient of the image. In a navigation context, the correspondence
between a salient point (called now ``landmark'') with its angular
position (azimuth) in respect with an absolute direction (north
given by a compass for instance) gives the position of that
landmark in the environment. At each time step, a set of 5
azimuths, corresponding to the 5 more salient landmarks in input the
image, constitutes the visual input
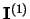 (the
angular confidence interval is
(the
angular confidence interval is  , so that the number of
visual entries is
, so that the number of
visual entries is  ).
).
Dauce Emmanuel
2003-04-08